思量。能几许,忧愁风雨,一半相妨。又何须抵死,说短论长。
——《满庭芳》宋/苏轼
GitHub Pages服务对与每一个用户开放username.github.io的域名解析和托管,如果你是普通用户,gh-page服务将仅对公有仓库开放,将仓库转为私有后gh-page停止解析和更新;对于学生Pro和付费Pro及以上等级用户,gh-page服务将同时对公有和私有仓库提供服务,然而Travis CI仅对公有仓库免费使用。
综上,本文面向于想使用GitHub Pages服务应用于私有仓库 的大家伙。
P.S. 把托管gh-page的仓库私有化可以减少隐私泄露。但,所有(部署分支的)文件仍然可以被爬取/扫描。
前言 之前一直用最简洁直白的GitHub Pages+Jekyll反正没有关注度不是嘛)。
近期因为疾控问题在家思思发抖,但学习和工作不能停,就干些一直以来没时间做/没接触的事情。
把gh-pages仓库私有
使用Hexo替代Jekyll
使用Github Action实现自动部署
使用ssh-keygen生成秘钥对实现部署 1 2 3 4 5 # set up private key for deploy mkdir -p ~/.ssh/ echo "$ACTION_DEPLOY_KEY" | tr -d '\r' > ~/.ssh/id_rsa # 配置秘钥 chmod 600 ~/.ssh/id_rsa ssh-keyscan github.com >> ~/.ssh/known_hosts
使用github personal access token实现部署 类似于 Google 两步验证中的备用验证码 ,不过google token是单次生成(可见/查询)使用后销毁,github personal token是单次生成销毁(不可见)多次使用。
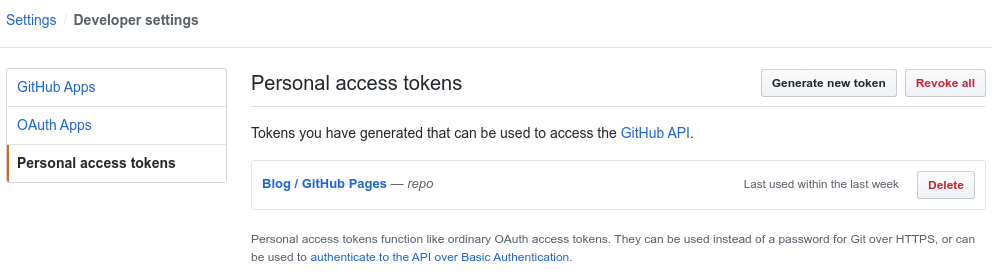
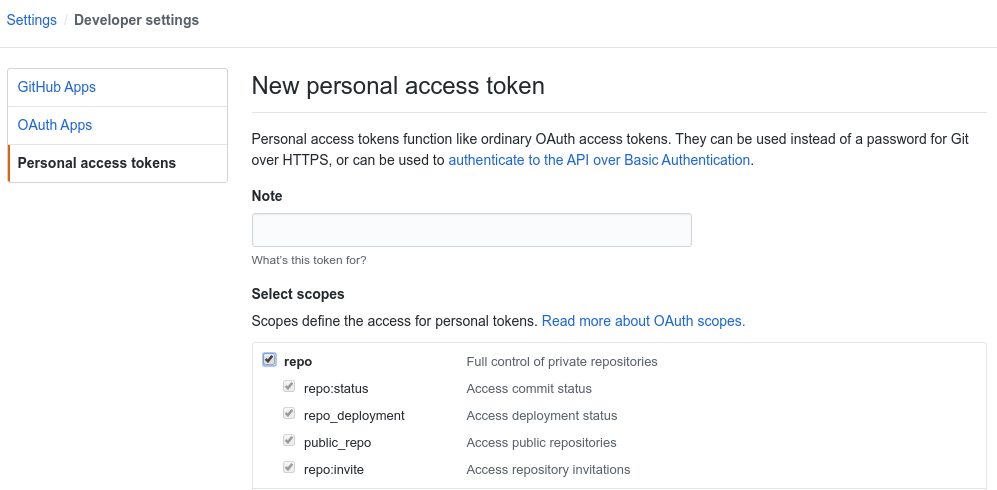
依次进入 Settings >> Developer settings >> Personal access tokens,点击 Generate new token。
部署部落格仅需要对repo的读写权限。此页面关闭之后 token 将不可见(快记下来!!)。
设置仓库 因为gh-pages服务默认部署的分支是master,所以有如下两种常见的仓库设置方法:
双仓库:仓库A用于存储hexo源文件,仓库B(xxx.github.io)用于hexo生成文件的部署,push A触发GitHub Action更新部署仓库B
单仓库:source分支用于存储hexo源文件,master分支用于hexo生成文件的部署,push source触发GitHub Action更新master并部署gh-pages
这里我采用的是单仓库双分支的设置,注意不要手贱merge了就好,不然还要花时间(action刷新master之后history会消失)。
上一步生成的 token 我们不能以明文形式存放,所以要设置为仓库的 Secrets,这样就可用 Secrets 隐式引用 token。依次进入(仓库的)setting >> Secrets >> Add a new secret,名称填 GITHUB_ACCESS_TOKEN,内容填刚刚的token。
配置 GitHub Action 修改 Hexo 的 _config.yml,将下面 id 和 仓库名修改为自己的。
1 2 3 4 deploy: type: git repo: https://[email protected] /your-github-id/your-github-repo-name.git branch: master
在 Hexo 根目录下新建 .github/workflows/blogci.yml,内容如下,将 git 的信息修改为自己的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 name: BlogCI on: [push ]jobs: build: runs-on: ubuntu-latest steps: - name: Download Source file uses: actions/checkout@v2 with: ref: source - name: Prepare Node env uses: actions/setup-node@v1 with: node-version: "10.x" - name: Set Env env: GITHUB_ACCESS_TOKEN: ${{ secrets.GITHUB_ACCESS_TOKEN }} run: | git config --global user.name 'my_name' # github用户名 git config --global user.email 'my_email' # github邮箱 sed -i "s/GITHUB_ACCESS_TOKEN/$GITHUB_ACCESS_TOKEN/g" ./_config.yml - name: Hexo run: | npm i -g hexo-cli npm i hexo clean && hexo g && hexo d
最后也可以采用另一种写法(使用局部安装避免npm安装依赖出错):
1 2 3 4 5 6 - name: Hexo run: | npm install hexo npm install npx hexo clean npx hexo g -d
保存后推送到 GitHub,再进入 Actions 会发现 BlogCI 已经在工作。
价格 目前GitHub Action采用免费时长的营销策略:
对于普通用户每个月可以免费使用2000分钟
对于Pro用户每个月免费使用3000分钟
据我统计一般成功的推送action执行时间在40~60s之间,执行时间较长的(3~5min)一般都是出错了 :(
按这个时间进行估算,用户在action上无需额外消费 :)
Reference
gh-pages服务 https://pages.github.com/
Jekyll部落格框架 https://jekyllrb.com/
Google备用验证码 https://support.google.com/accounts/answer/1187538
参考的Blog 有改进和勘误 https://rook1e.com/p/6.html
Hexo中文文档 https://hexo.io/zh-cn/docs/