一生孤寂,痴心错付.
「度量学习(Metric Learning)」即学习一个度量空间,在该空间中的学习异常高效,这种方法用于小样本分类时效果很好,不过度量学习方法的效果尚未在回归或强化学习等其他元学习领域中验证。在人脸识别,指纹识别等开集分类的任务中,类别数往往很多而类内样本数比较少。在这种情况下,基于深度学习的分类方法常表现出一些局限性,如缺少类内约束,分类器优化困难等。而这些局限可以通过深度度量学习来解决。
近日,Facebook AI 和 Cornell Tech 的研究者在论文预印本平台 arXiv 上公布了最新研究论文,声称这十三年来深度度量学习领域的研究进展「实际上并不存在」。
论文链接:https://arxiv.org/pdf/2003.08505.pdf
理论攀升原地踏步
研究者发现,度量学习的这些论文在实验设置方面存在多种缺陷,比如不公平的实验比较,测试集标签泄露,不合理的评价指标等。于是,他们提出了一种新的评估方法来重新审视度量学习领域的多项研究。最后,他们通过实验表明,现有论文宣称的那些改进实在是「微不足道」,近几年的 ArcFace,SoftTriple,,CosFace 等十种算法,和十三年前的 Contrastive,Triplet 基线方法相比,并没有什么实质性的提高。
研究者发现,这些论文过分夸大了自己相对于两种经典方法——对比损失(contrastive loss)和三元组损失(triplet loss)——的改进。许多论文表示,自己方法的性能超出了对比损失一倍还多,比三元组损失也高出 50% 以上。这些提升是因为这些损失造成了非常低的准确性。
这些数据有一些是来源于 2016 年的提升结构损失论文,在他们的对比损失和三元组损失的实现中,他们每批采样 N/2 样本对和 N/3 样本三元组(N 是批的大小)。因此,他们只用到了每批里的一小部分数据信息。
他们将三元组的 margin 设置为 1,而最优的值大约是 0.1。尽管有这些实现缺陷,大多数论文仍旧只是简单地引用这些较低的数字,而不是依靠自己实现损失去获得一个更有意义的基线。
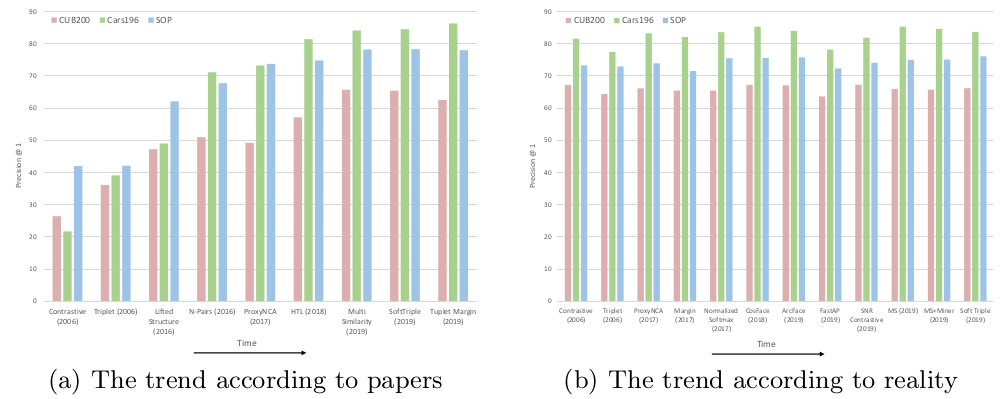
通过这些基线损失所呈现的良好实现,公平竞争环境和机器学习实践,研究者获得了如图所示的趋势图——事实上它似乎是平滑的走向。这表明无论是在 2006 年还是在 2019 年,各种方法的性能都是相似的。换句话说,度量学习算法并没有取得论文中所说的那么夸张的进展,论文中没有提到的前沿论文也值得怀疑。也就是说,论文宣称的改进是节节攀升的,但实际情况却是原地踏步。
论文存在的缺陷
不公平的比较
为了宣称新算法的性能比已有的方法要好。尽可能多地保持参数不变是很重要的。这样便能够确定性能的优化是新算法带来的提升,而不是由额外的参数造成的。但现有的度量学习论文的研究情况却不是如此。
提高准确率最简单的方法之一是优化网络架构,但这些论文却没有保证这项基本参数固定不变。度量学习中架构的选择是非常重要的。在较小的数据集上的初始的准确率会随着所选择的网络而变化。2017 年一篇被广泛引用的论文用到了 ResNet50,然后声称性能得到了巨大的提升。这是值得质疑的,因为他们用的是 GoogleNet 作比较,初始准确率要低得多。
通过测试集反馈进行训练
该领域大多数论文会将每个数据集分开,类中的前 50% 用作训练集,剩下的部分用作测试集。训练过程中,研究者会定期检查模型在测试集上的准确率。也就是,这里没有验证集,模型的选择和超参数的调整是通过来自测试集的直接反馈完成的。一些论文并不定期检查性能,而是在预先设置好的训练迭代次数之后报告准确率。在这种情况下,如何设置迭代次数并不确定,超参数也仍然是在测试集性能的基础上调整的。这种做法犯了机器学习研究的一个大忌。依靠测试集的反馈进行训练会导致在测试集上过拟合。因此度量学习论文中所阐述的准确率的持续提升会被质疑。
常用的准确率度量的缺点
为了报告准确率,大多数度量学习论文用到的指标是 Recall@K,标准化互信息(NMI)以及 F1 分值。但这些真的是最佳度量标准吗?图 1 展示了三种嵌入空间,虽然它们有不同的特性,但每个 Recall@1 的分值都接近 100%,说明这个指标基本上提供不了什么信息。
新的评估方法的提出
以上种种缺陷造成了度量学习领域的「虚假繁荣」。因此研究者提出了一种新的评估方法,希望能够对损失函数进行恰当的评估。
公平的比较和复现
所有的实验都是在 PyTorch 上进行的,用到了 ImageNet 来预训练 BN-Inception 网络。训练过程中冻结 BatchNorm 参数,以减少过拟合。批大小设置为 32。
训练过程中,图像增强通过随机调整大小的裁剪策略来完成。所有的网络参数都用学习率为 1e-6 的 RMSprop 进行优化。在计算损失函数之前和评估过程中,对嵌入进行 L2 归一化。
通过交叉验证进行超参数搜索
为了找到最好的损失函数超参数,研究运行了 50 次贝叶斯优化迭代,每次迭代均包括 4 折交叉验证:类中的第一半用来交叉验证,创建 4 个分区,前 0-12.5% 是第一个分区,12.5-25% 是第二个分区,以此类推。第二半用来做测试集,这和度量学习论文使用多年的设置相同,目的是便于和之前的论文结果做比较。
超参数都被优化到能最大化验证精确度的平均值。对于最佳超参数,将加载每个训练集分区的最高准确率检查点,测试集的嵌入是经过计算和 L2 归一化的,然后计算准确率。
更有信息量的准确率度量指标
研究者用 Mean Average Precision at R (MAP@R) 来度量准确度,这一指标综合了平均精度均值和 R 精度的思想。
R 精度的一个弱点是,它没有说明正确检索的排序。因此,该研究使用 MAP@R。MAP@R 的好处是比 Recall@1 更有信息量。它可以直接从嵌入空间中计算出来,而不需要聚类步骤,也很容易理解。它奖励聚类良好的嵌入空间。
众说纷纭: 十年错付?
在这篇论文出现以后,很多人在讨论:度量学习是否已经到了一个瓶颈期?我们还要继续在这个研究方向上前进吗?第一个问题的答案是肯定的,第二个问题的答案也是肯定的。其实每个领域经历过一段长时间的发展以后,都必然会有研究者回过头来进行反思。学术研究也适用于这条定律:「走得太远,忘记了为什么出发。」
王晋东不在家
我的理解是,每当一个研究领域出现一些rethinking,revisiting,comprehensive analysis等类型的文章时,往往都说明了几个现象:
- 这个领域发展的还可以,出现了很多相关的工作可以参考;
- 这个领域的文章同质化太严重,到了传说中的“瓶颈期”;
- 研究人员思考为什么已经有这么多好工作,却好像觉得还差点意思,还“不够用”,“不好用”,“没法用”。
其实这对于研究而言是个好事。“Research”的这个”Re”,说的就是这个意思啦。 我们在一条路上走了太久,却常常忘记了为什么出发。此时需要有些人(常常是大佬,普通人不敢,哈哈)敢于“冒天下之大不韪”,出来给大家头上浇盆冷水,重新思考一下这个领域出现了什么问题。哲学上也有“否定之否定”规律嘛。
王珣
本人两年前为了做硕士毕设,单枪匹马入坑deep metric learning,然后在这个坑里摸爬了两年。其实这个文章里说的坑我也踩过大部分,我心里也是知道这个领域的大部分方法(包括我自己的MS Loss)提升没有文章里宣称的那么大,至于这些方法的“进步”到底来自哪里,直接说其实是以下三部分:
- 调参技术或者说tricks (比如freeze bn,lr_mul等),但是这个其实只在CUB Cars196这两个特别小的数据集有用,在SOP, InShop 其实完全没有意义,我在开源的代码里写了这个点。
- 方法本身的提高,即便是在这个check reality 论文列出的复现结果表格里,可以看到MS Loss确实是当时的SOTA。 而且,我在ablation study并没有刻意压低结果,使用的都是自己复现的结果(都是一致的试验设置),提升也没有夸大,对比对象的代码我也基本开源。
- 关键点是:Batch size, 这一点,我没有写在MS论文的正文里,只写在附录里了。其实batch size是方法提升的核心,越大的mini-batch size可以大幅提升大规模检索数据的结果。其他有些基于pair weighting 或者 sampling 文章,你稍微读读试验设置,也是如此,他说了一堆故事,最后做实验,为了在sop 和 inshop的效果,用的batch size很大。
其实每个领域都有水文,绝不限于deep metric learning,没必要嘲笑。历史滚滚,百分之九十的顶会论文并不会激起波澜,终成废纸,很多时候,文章存在的意义也许是为了毕业,也许是为了工作,但并不是学术进步。因此,也没有必要对顶会论文有着统一的过高期望,顶会论文和顶会论文的差距也是很大的。想想Resnet, 一文胜千文。不过这样的打脸文确实比水文有意义的多,可以促进领域更加健康的发展,即便我的ms loss也是打脸对象之一。我也希望自己做论文,尽量做到诚实公正。做的工作虽浅薄,也希望可以给读者带来一些有益的启发,最起码不把读者带到沟里,无愧于本心。
杨个毛
我觉得需要解决的问题是,除了文章以外有什么权威的渠道去对 state of the art 进行更新和维护。
就比如王珣的回答里给出的心路历程。我觉得他写文章的方法没错,因为所有人都是这么干的。
但是我们知道,科学的实验就是应该控制变量。从这个科学方法的观点,“batch size 加大能涨点”这种事情需要一个合理合法的渠道告知整个学术界,这样,学术界的实验才能一直在一个 relevant 的 baseline 上进行。
这种责任下放给单个论文作者是不好的,因为这种事情又没法作为论文的主要贡献说出来,只能以 “我顺手改了个batch size” “我顺手加了几层 BN” “我顺手换了个 backbone” 这种可疑的方式推动这个 baseline 前进。
这里的矛盾是一件事的思想上的启发性和方法论上的重要性可能是矛盾的。“把 batch size 改大”这种事情给人的启发为0,但是方法论上却是重要的——你必须把所有方法拉齐到现代水平并且好好调超参,对比才有意义。
现在的问题是,incremental 改进都没有启发性,没有启发性就假装不重要,假装不重要就看不见,看不见就当不存在。这就如同你筑个大坝硬是把河拦住,那你的必然结局就是山洪爆发。
Reference
- https://www.zhihu.com/question/394204248
- https://www.jiqizhixin.com/articles/2020-05-16-5
- https://arxiv.org/pdf/2003.08505.pdf

